Une équipe de scientifiques a compilé un volume extraordinaire de de textes en arabe en employant des techniques très ingénieuses pour saisir les nuances de la langue.
Le descriptif
Signe des temps à venir, la startup Cerebras Systems vient d’annoncer une association avec Inception, une filiale de la société d’investissement G42 des Émirats arabes unis. L’idée est de créer le plus grand modèle linguistique ouvert au monde pour l’arabe, une langue parlée par environ 400 millions de personnes.
L’utilisation du programme, appelé Jais-Chat, se fait de la même manière que la saisie dans l’invite de Chat-GPT, à ceci près que Jais-Chat peut prendre et produire des textes en arabe en entrée et en sortie. Il peut, par exemple, écrire une lettre en arabe lorsqu’on lui demande de le faire en anglais :
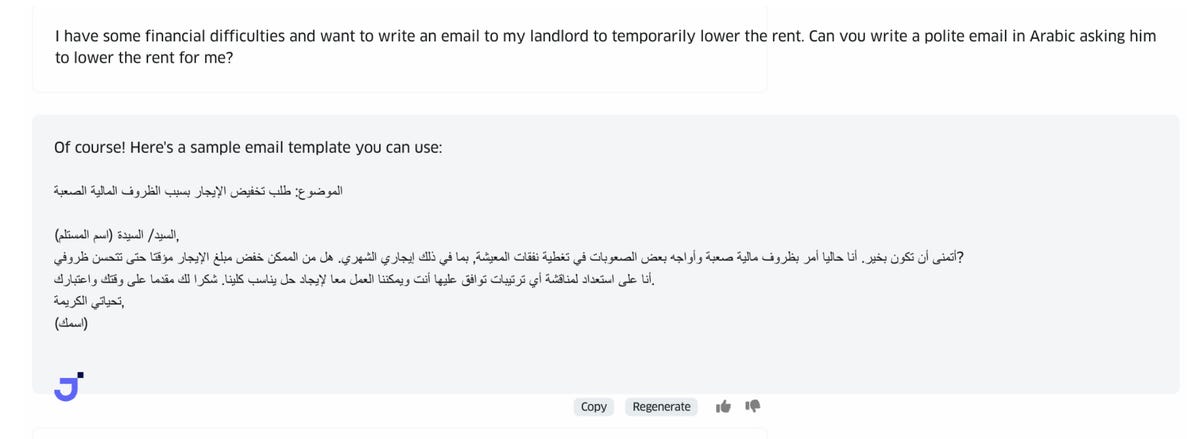
Ou il peut prendre une invite en langue arabe et générer une réponse en arabe :

Entraîné sur un corpus spécial de textes arabes important, le programme renonce à l’approche typique qui consiste à construire un programme généraliste qui traite des centaines de langues, dans de nombreux cas de manière médiocre, et se concentre exclusivement sur les traductions anglaises et arabes.
Jais-Chat a obtenu 10 points de plus que LlaMA 2
Lors de tests – tels que le test QCM MMLU de l’Université de Californie à Berkeley, et le test HellaSwag de l’Institut Allen pour l’IA – Jais-Chat a obtenu 10 points de plus que les principaux LLM tels que LlaMA 2 de Meta. Il a battu les meilleurs programmes open-source tels que Bloom de Big Science Workshop de cette année, et il a également battu les modèles de langage spécialisés construits exclusivement pour l’arabe.
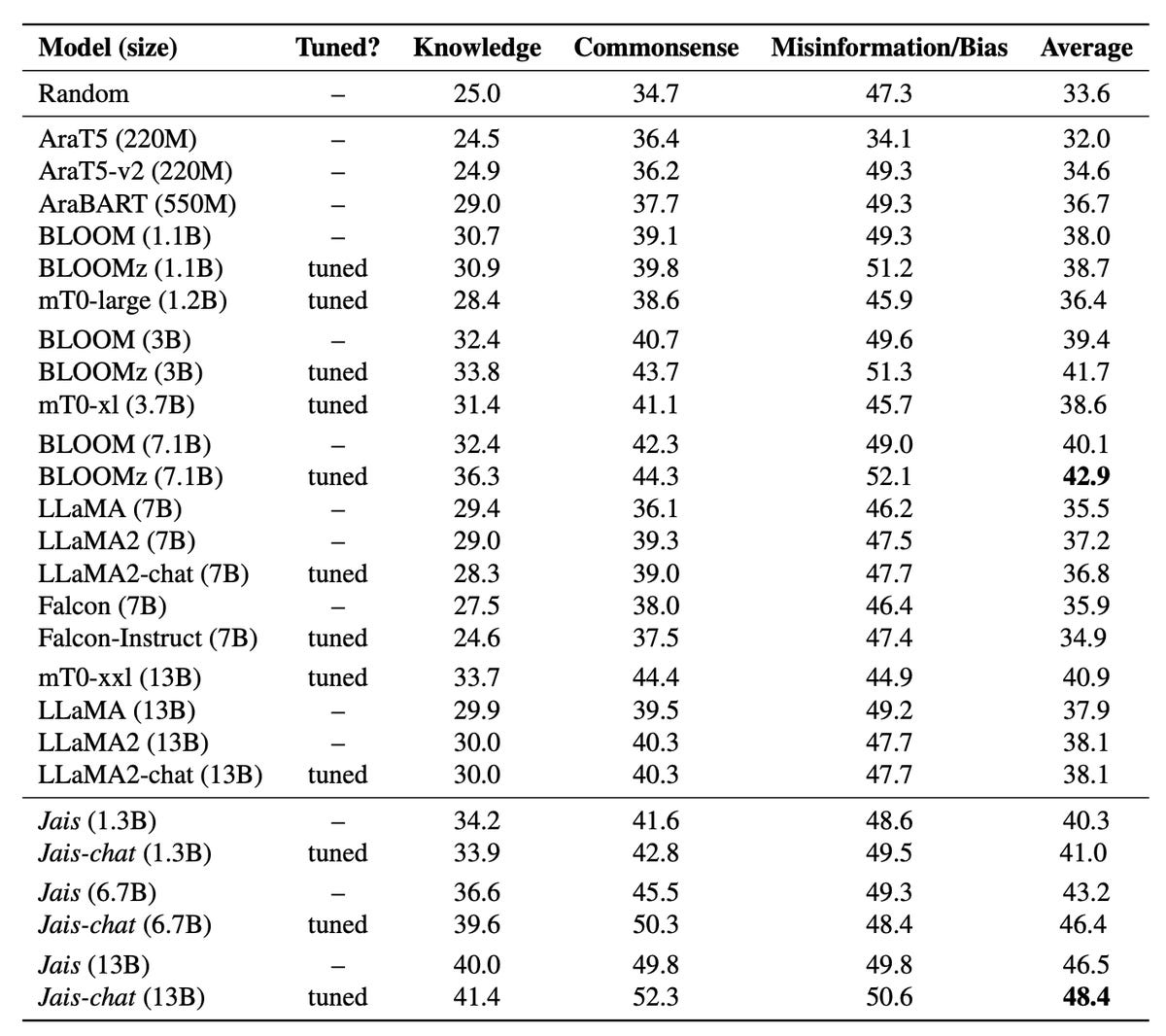
Jais-Chat obtient de meilleurs résultats à plusieurs tests en arabe par rapport à des modèles beaucoup plus grands tels que LlaMA 2 de Meta. Inception
« Beaucoup d’entreprises parlent de démocratiser l’IA », explique Andrew Feldman, cofondateur et PDG de Cerebras, lors d’un entretien avec ZDNET. « Nous donnons à 400 millions d’arabophones une voix dans l’IA. C’est cela démocratiser l’IA. C’est la langue principale de 25 pays ».
La disparité linguistique dans le secteur de l’IA fait l’objet d’une attention considérable depuis un certain temps déjà. L’initiative « No Language Left Behind » (NLLB), lancée l’année dernière par Meta Properties, travaille sur le traitement simultané de 200 langues, en mettant l’accent sur les langues dites « à faibles ressources », c’est-à-dire celles qui ne disposent pas d’un vaste corpus de textes en ligne pouvant être utilisés pour former les modèles.
« Si seulement 25,9 % des internautes parlent anglais, 63,7 % de tous les sites web sont en anglais »
Comme le notent les auteurs de Meta, les études menées dans ce domaine « indiquent que si seulement 25,9 % des internautes parlent anglais, 63,7 % de tous les sites web sont en anglais ».
« La vérité, c’est que les plus grands ensembles de données reposent sur le scraping de de l’internet, et l’internet est principalement en anglais, ce qui est une situation vraiment malheureuse », a déclaré M. Feldman.
Les tentatives pour combler le fossé linguistique dans le domaine de l’IA font appel à des programmes d’IA généralistes, tels que le NLLB de Meta. Cependant, ces programmes ne parviennent pas pour l’instant à s’améliorer dans un certain nombre de langues, y compris des langues à faibles ressources comme l’oromo (originaire d’Éthiopie et du Kenya), mais aussi des langues dont le matériel de traduction est pourtant très répandu, comme le grec et l’islandais.
A rebours des modèles multimodaux
Les programmes dits multimodaux, tels que le successeur du NLLB, SeamlessM4T de Meta tentent d’effectuer de nombreuses tâches différentes dans des dizaines de langues à l’aide d’un seul modèle, y compris la transcription de texte en parole et la génération de texte à partir de la parole. Cela peut alourdir l’ensemble du processus avec des objectifs supplémentaires.
Au lieu d’une approche généraliste ou multimodale, Inception et Cerebras ont construit un programme qui ne s’entraîne qu’à l’arabe et à l’anglais. Comment ?
- Ils ont pour cela créé un ensemble de données spécial de textes en langue arabe. Ils ont compilé 55 milliards de tokens de données provenant d’une myriade de sources telles que Abu El-Khair, une collection de plus de 5 millions d’articles, couvrant une période de 14 ans, provenant de sources d’information majeures ; la version arabe de Wikipedia ; et les transcriptions des Nations unies, entre autres. Ensuite, les auteurs sont parvenus à augmenter les données de formation en langue arabe de 55 milliards de tokens à 72 milliards en effectuant une traduction automatique de textes anglais en arabe.
- Les auteurs ont ensuite multiplié par 1,6 l’échantillonnage du texte en langue arabe, augmentant ainsi les données en langue arabe à un total de 116 milliards de tokens.
- Les auteurs ont adopté une autre approche novatrice. Ils ont combiné les textes en arabe et en anglais avec des milliards de tokens provenant d’extraits de code informatique recueillis sur GitHub.
L’ensemble de données final comprend 29 % d’arabe, 59 % d’anglais et 12 % de code.
Un tokenizer spécifique
Les chercheurs ne se sont pas contentés d’utiliser un ensemble de données spécial. Ils ont également employé plusieurs techniques spécifiques pour représenter le vocabulaire arabe.
Les chercheurs ont pour ce faire construit leur propre « tokenizer ». Le tokenizer habituel utilisé par des programmes tels que GPT-3 « est principalement formé sur des corpus anglais », écrivent les chercheurs. De sorte que les mots arabes courants « sont sur-segmentés en caractères individuels […], ce qui diminue les performances du modèle et augmente le coût de calcul ».
Les chercheurs ont également utilisé un algorithme d' »intégration », ALiBi, développé l’année dernière par l’Allen Institute et Meta. Cet algorithme est beaucoup plus performant pour traiter les contextes très longs, c’est-à-dire les entrées d’un modèle linguistique tapées à l’invite ou rappelées de la mémoire.
Le code de Jais est publié sous licence Apache 2.0 et est disponible sur Hugging Face
« Nous cherchions à saisir les nuances linguistiques de l’arabe et les références culturelles », explique M. Feldman, qui a beaucoup voyagé au Moyen-Orient. « Et ce n’est pas facile quand la majeure partie du modèle est en anglais ».
Grâce à ces modifications, le résultat est un modèle linguistique appelé Jais, et son application de chat, Jais-Chat, mesurant 13 milliards de « paramètres », les poids neuronaux qui forment les éléments actifs critiques du réseau neuronal. Jais est basé sur l’architecture GPT-3 conçue par OpenAI, une version dite « décodeur » du Transformer de Google datant de 2017.
Le code du programme Jais est publié sous la licence de code source Apache 2.0 et est disponible au téléchargement sur Hugging Face. Une démonstration de Jais peut être utilisée en s’inscrivant sur une liste d’attente. Les auteurs prévoient de rendre l’ensemble de données public « dans un avenir proche », selon M. Feldman.
Les programmes ont été exécutés sur ce que Cerebras appelle « le plus grand supercalculateur au monde pour l’IA », appelé Condor Galaxy 1, qui a été construit pour G42 et a été dévoilé le mois dernier.
La machine est composée de 32 ordinateurs d’IA spécialisés de Cerebras, les CS-2, dont les puces contiennent collectivement un total de 27 millions de cœurs de calcul, 41 téraoctets de mémoire et 194 trillions de bits par seconde de bande passante. Ils sont supervisés par 36 352 processeurs de serveur EPYC x86 d’AMD. Les chercheurs ont utilisé une partie de cette capacité, soit 16 machines, pour former et « affiner » Jais.
Avec ses 13 milliards de paramètres, le programme est très performant. Il s’agit d’un réseau neuronal relativement petit, comparé à des éléments tels que le GPT-3, qui compte 175 milliards de paramètres.
« Ses capacités pré-entraînées surpassent tous les modèles arabes open-source connus », écrivent les chercheurs, « et sont comparables aux modèles anglais open-source qui ont été entraînés sur des ensembles de données plus importants ».
Comme le notent les auteurs, l’ensemble de données arabes de 72 milliards de tokens ne serait normalement pas suffisant pour un modèle de plus de 4 milliards de paramètres, selon la règle empirique de l’IA connue sous le nom de « loi de Chinchilla », formulée par les chercheurs de DeepMind de Google.
En fait, non seulement Jais-Chat dans sa forme à 13 milliards de paramètres surpasse LlAMA 2, mais dans une version plus petite de leur programme avec seulement 6,7 milliards de paramètres, ils sont également en mesure d’obtenir de meilleurs résultats aux mêmes tests tels que MMLU et HellaSwag.
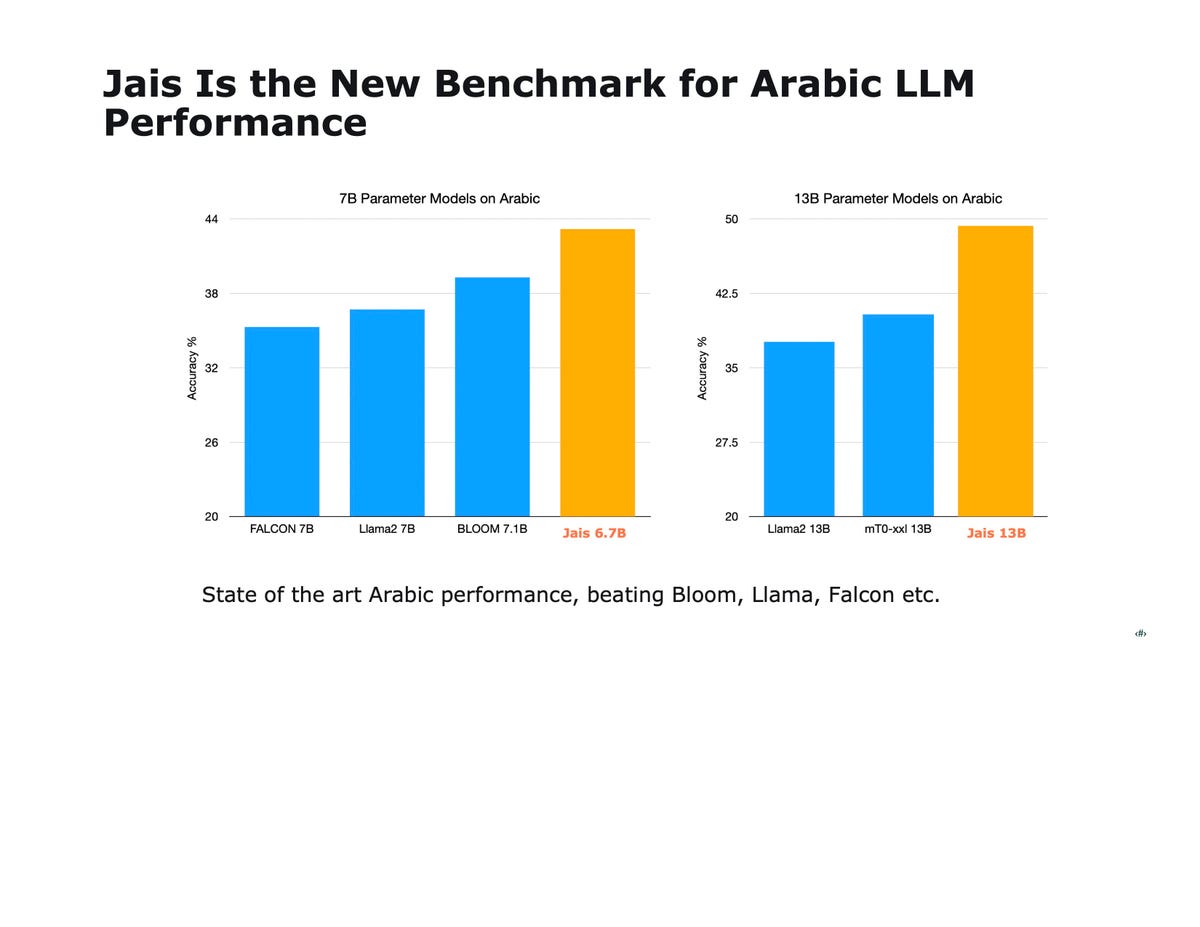
Jais-Chat obtient de meilleurs résultats à plusieurs tests en arabe par rapport à des modèles beaucoup plus grands tels que LlaMA 2 de Meta. Inception
« Ce qui était intéressant, c’est que l’arabe améliorait aussi l’anglais », a déclaré M. Feldman, se référant aux performances de Jais. « Nous avons fini par obtenir un modèle aussi performant que LlaMA en anglais, bien que nous l’ayons entraîné sur environ un dixième des données.
Articles sources :









