Continuons avec les informations relatives au groupe Alphabet :

L’article est certes un peur long ; mais trop intéressant !
While no doctor, nurse, or pharmacist wants to make a mistake that harms a patient, research shows that 2% of hospitalized patients experience serious preventable medication-related incidents that can be life-threatening, cause permanent harm, or result in death. There are many factors contributing to medical mistakes, often rooted in deficient systems, tools, processes, or working conditions, rather than the flaws of individual clinicians (IOM report). To mitigate these challenges, one can imagine a system more sophisticated than the current rules-based error alerts provided in standard electronic health record software.
The system would identify prescriptions that looked abnormal for the patient and their current situation, similar to a system that produces warnings for atypical credit card purchases on stolen cards. However, determining which medications are appropriate for any given patient at any given time is complex — doctors and pharmacists train for years before acquiring the skill. With the widespread use of electronic health records, it may now be feasible to use this data to identify normal and abnormal patterns of prescriptions. In an initial effort to explore solutions to this problem, we partnered with UCSF’s Bakar Computational Health Sciences Institute to publish “Predicting Inpatient Medication Orders in Electronic Health Record Data” in Clinical Pharmacology and Therapeutics, which evaluates the extent to which machine learning could anticipate normal prescribing patterns by doctors, based on electronic health records.
Similar to our prior work, we used comprehensive clinical data from de-identified patient records, including the sequence of vital signs, laboratory results, past medications, procedures, diagnoses and more. Based on the patient’s current clinical state and medical history, our best model was able to anticipate physician’s actual prescribing decisions three quarters of the time.
Bien qu’aucun médecin, infirmier ou pharmacien ne souhaite commettre une erreur qui porte préjudice à un patient, les recherches montrent que 2 % des patients hospitalisés sont victimes d’incidents médicamenteux graves et évitables qui peuvent mettre leur vie en danger, causer des dommages permanents ou entraîner la mort. De nombreux facteurs contribuent aux erreurs médicales, qui trouvent souvent leur origine dans des systèmes, des outils, des processus ou des conditions de travail déficients, plutôt que dans les défauts de certains cliniciens (rapport du IOM). Pour atténuer ces difficultés, on peut imaginer un système plus sophistiqué que les alertes d’erreur basées sur des règles actuellement fournies par les logiciels de dossiers médicaux électroniques standard. Le système identifierait les prescriptions qui semblent anormales pour le patient et sa situation actuelle, à l’instar d’un système qui produit des avertissements pour des achats atypiques sur des cartes de crédit volées. Cependant, déterminer quels médicaments sont appropriés pour un patient donné à un moment donné est complexe – les médecins et les pharmaciens s’entraînent pendant des années avant d’acquérir cette compétence. Avec l’utilisation généralisée des dossiers médicaux électroniques, il est peut-être désormais possible d’utiliser ces données pour identifier les schémas normaux et anormaux des prescriptions. Dans un premier effort pour explorer des solutions à ce problème, nous nous sommes associés au Bakar Computational Health Sciences Institute de l’UCSF pour publier « Predicting Inpatient Medication Orders in Electronic Health Record Data » dans Clinical Pharmacology and Therapeutics, qui évalue dans quelle mesure l’apprentissage automatique pourrait anticiper les modèles de prescription normaux des médecins, sur la base des dossiers médicaux électroniques. Comme dans nos travaux précédents, nous avons utilisé des données cliniques complètes provenant de dossiers de patients dépersonnalisés, notamment la séquence des signes vitaux, les résultats de laboratoire, les médicaments, les procédures et les diagnostics antérieurs, etc. Sur la base de l’état clinique actuel du patient et de ses antécédents médicaux, notre meilleur modèle a permis d’anticiper les décisions de prescription réelles des médecins dans les trois quarts des cas.
The dataset used for model training included approximately three million medication orders from over 100,000 hospitalizations. It used retrospective electronic health record data, which was de-identified by randomly shifting dates and removing identifying portions of the record in accordance with HIPAA, including names, addresses, contact details, record numbers, physician names, free-text notes, images, and more. The data was not joined or combined with any other data.
All research was done using the open-sourced Fast Healthcare Interoperability Resources (FHIR) format, which we’ve previously used to make healthcare data more effective for machine learning. The dataset was not restricted to a particular disease or therapeutic area, which made the machine learning task more challenging, but also helped to ensure that the model could identify a larger variety of conditions; e.g. patients suffering from dehydration require different medications than those with traumatic injuries. We evaluated two machine learning models: a long short-term memory (LSTM) recurrent neural network and a regularized, time-bucketed logistic model, which are commonly used in clinical research. Both were compared to a simple baseline that ranked the most frequently ordered medications based on a patient’s hospital service (e.g., General Medical, General Surgical, Obstetrics, Cardiology, etc.) and amount of time since admission. Each time a medication was ordered in the retrospective data, the models ranked a list of 990 possible medications, and we assessed whether the models assigned high probabilities to the medications actually ordered by doctors in each case.
As an example of how the model was evaluated, imagine a patient who arrived at the hospital with signs of an infection. The model reviewed the information recorded in the patient’s electronic health record — a high temperature, elevated white blood cell count, quick breathing rate — and estimated how likely it would be for different medications to be prescribed in that situation. The model’s performance was evaluated by comparing its ranked choices against the medications that the physician actually prescribed (in this example, the antibiotic vancomycin and sodium chloride solution for rehydration).
L’ensemble de données utilisé pour la formation du modèle comprenait environ trois millions d’ordonnances de médicaments provenant de plus de 100 000 hospitalisations. Il a utilisé des données rétrospectives de dossiers médicaux électroniques, qui ont été dépersonnalisées en décalant aléatoirement les dates et en supprimant les parties identifiantes du dossier conformément à la loi HIPAA, notamment les noms, les adresses, les coordonnées, les numéros de dossier, les noms des médecins, les notes en texte libre, les images, etc. Les données n’ont pas été jointes ou combinées avec d’autres données. Toutes les recherches ont été effectuées en utilisant le format FHIR (Fast Healthcare Interoperability Resources) en libre accès, que nous avons déjà utilisé pour rendre les données de santé plus efficaces pour l’apprentissage automatique. L’ensemble de données n’était pas limité à une maladie ou à un domaine thérapeutique particulier, ce qui a rendu la tâche d’apprentissage automatique plus difficile, mais a également permis de s’assurer que le modèle pouvait identifier une plus grande variété de conditions ; par exemple, les patients souffrant de déshydratation ont besoin de médicaments différents de ceux qui souffrent de blessures traumatiques. Nous avons évalué deux modèles d’apprentissage automatique : un réseau neuronal récurrent à mémoire à long court terme (LSTM) et un modèle logistique régularisé et centré sur le temps, qui sont couramment utilisés dans la recherche clinique. Les deux modèles ont été comparés à un modèle de base simple qui classait les médicaments les plus fréquemment commandés en fonction du service hospitalier du patient (par exemple, médecine générale, chirurgie générale, obstétrique, cardiologie, etc. ) et le temps écoulé depuis l’admission. Chaque fois qu’un médicament a été prescrit dans les données rétrospectives, les modèles ont classé une liste de 990 médicaments possibles, et nous avons évalué si les modèles ont attribué des probabilités élevées aux médicaments effectivement prescrits par les médecins dans chaque cas. Pour illustrer la manière dont le modèle a été évalué, imaginons un patient qui arrive à l’hôpital avec des signes d’infection. Le modèle a examiné les informations enregistrées dans le dossier médical électronique du patient – une température élevée, un taux élevé de globules blancs, un rythme respiratoire rapide – et a estimé la probabilité que différents médicaments soient prescrits dans cette situation. La performance du modèle a été évaluée en comparant ses choix classés avec les médicaments que le médecin a effectivement prescrits (dans cet exemple, l’antibiotique vancomycine et une solution de chlorure de sodium pour la réhydratation).
Our best-performing model was the LSTM model, a class of models particularly effective for handling sequential data, including text and language. These models are capable of capturing the ordering and time recency of events in the data, making them a good choice for this problem. Nearly all (93%) top-10 lists contained at least one medication that would be ordered by clinicians for the given patient within the next day. Fifty-five percent of the time, the model correctly placed medications prescribed by the doctor as one of the top-10 most likely medications, and 75% of ordered medications were ranked in the top-25. Even for ‘false negatives’ — cases where the medication ordered by doctors did not appear among the top-25 results — the model highly ranked a medication in the same class 42% of the time. This performance was not explained by the model simply predicting previously prescribed medications. Even when we blinded the model to previous medication orders, it maintained high performance.
It’s important to remember that models trained this way reproduce physician behavior as it appears in historical data, and have not learned optimal prescribing patterns, how these medications might work, or what side effects might occur. However, learning ‘normal’ is a starting point to eventually spot abnormal, potentially dangerous orders. In our next phase of research, we will examine under which circumstances these models are useful for finding medication errors that could harm patients. The results from this exploratory work are early first steps towards testing the hypothesis that machine learning can be applied to build systems that prevent mistakes and help to keep patients safe. We look forward to collaborating with doctors, pharmacists, other clinicians, and patients as we continue research to quantify whether models like this one are capable of catching errors, keeping patients safe in the hospital.
From Google AI Blog
Issued on Thursday, April 2, 2020
By Kathryn Rough, Research Scientist and Alvin Rajkomar, MD, Google Health
Notre modèle le plus performant était le modèle LSTM, une classe de modèles particulièrement efficace pour traiter les données séquentielles, y compris le texte et le langage. Ces modèles sont capables de saisir l’ordre et la récence des événements dans les données, ce qui en fait un bon choix pour ce problème. La quasi-totalité (93 %) des listes des 10 premiers médicaments contenait au moins un médicament qui serait commandé par les cliniciens pour le patient donné dans le jour suivant. Dans 55 % des cas, le modèle a correctement placé les médicaments prescrits par le médecin parmi les 10 médicaments les plus probables, et 75 % des médicaments commandés ont été classés dans les 25 premiers. Même pour les « faux négatifs », c’est-à-dire les cas où le médicament prescrit par le médecin ne figurait pas parmi les 25 premiers résultats, le modèle a classé correctement un médicament de la même classe dans 42 % des cas. Cette performance ne s’explique pas par le fait que le modèle prédit simplement les médicaments prescrits précédemment. Même lorsque nous avons rendu le modèle aveugle aux commandes de médicaments antérieures, il a maintenu une performance élevée.
Il est important de se rappeler que les modèles entraînés de cette manière reproduisent le comportement des médecins tel qu’il apparaît dans les données historiques, et qu’ils n’ont pas appris les modèles de prescription optimaux, comment ces médicaments pourraient fonctionner ou quels effets secondaires pourraient se produire. Cependant, l’apprentissage de la « normalité » est un point de départ pour repérer éventuellement les ordonnances anormales et potentiellement dangereuses. Dans notre prochaine phase de recherche, nous examinerons dans quelles circonstances ces modèles sont utiles pour détecter les erreurs de médication qui pourraient nuire aux patients. Les résultats de ce travail exploratoire sont les premiers pas vers la vérification de l’hypothèse selon laquelle l’apprentissage automatique peut être appliqué pour construire des systèmes qui empêchent les erreurs et contribuent à la sécurité des patients. Nous sommes impatients de collaborer avec des médecins, des pharmaciens, d’autres cliniciens et des patients afin de poursuivre les recherches visant à quantifier si des modèles comme celui-ci sont capables de détecter les erreurs et d’assurer la sécurité des patients à l’hôpital.

Peu d’éléments concernant Alphabet sont plus fascinants que son laboratoire de recherche futuriste, X. Des drones aux voitures sans conducteur, cette division ultrasecrète et libre d’action a donné naissance à certains des plus grands projets de la maison-mère de Google. Certains d’entre eux, comme l’entreprise de véhicules autonomes Waymo, sont devenus des entités à part entière au sein d’Alphabet. D’autres, comme l’entreprise de stockage d’énergie Malta, sont devenues des entreprises indépendantes. Ce département est dirigé par Astro Teller, et nous allons lister les projets en cours ; enfin ceux où il y a un peu d’information. Il faut bien voir que le groupe gagne plus que beaucoup d’argent et qu’il faut bien le dépenser.
En 2018, la société X d’Alphabet a annoncé explorer de nouvelles façons d’utiliser l’intelligence artificielle dans la production alimentaire. En octobre, elle a révélé que cette recherche se poursuivait dans le cadre d’un projet baptisé Mineral.
Mineral vise à changer l’agriculture en utilisant ce qu’il appelle l’agriculture « computationnelle ». En d’autres mots, il s’agit de trouver des moyens novateurs d’utiliser la technologie pour donner aux agriculteurs un meilleur aperçu de ce qui se passe dans leur champ. L’entreprise affirme qu’en suivant le développement des plantes, les cultivateurs peuvent mieux prévoir la taille et le rendement de la récolte, ce qui peut ensuite les aider à faire de meilleures projections de rendement.
Elliot Grant est à la tête du projet. Il était auparavant PDG de HarvestMark, une plateforme permettant de retracer les aliments jusqu’à leur source agricole.
L’un des éléments centraux de Mineral est constitué de buggys électriques alimentés par l’énergie solaire qui peuvent se déplacer dans un champ et capturer des données sur les cultures à l’aide de caméras et d’autres capteurs. Ces données seraient ensuite combinées à des images satellites, ainsi qu’à des données sur le sol et la météo, afin d’identifier des modèles et de donner aux agriculteurs une meilleure compréhension de la croissance de leurs cultures. L’équipe a déclaré qu’elle travaillait actuellement avec des sélectionneurs et des cultivateurs en Argentine, au Canada, aux États-Unis et en Afrique du Sud.
« Tout comme le microscope a conduit à une transformation de la manière dont les maladies sont détectées et gérées, nous espérons que de meilleurs outils permettront à l’industrie agricole de transformer la manière dont les aliments sont cultivés », a écrit le responsable du projet, dans un billet de blog.
Source : Blog.X.company – Bringing the era of computational agriculture to life
Autre article : Waymo teste sa technologie de conduite autonome dans une ville virtuelle
Publié sur Siècle Digital le 9 juillet 2021 par Stella Rosso

Lac-X travaille activement sur plusieurs projets d’accessoires électroniques, mais des sources ont déclaré que l’un des plus prometteurs est un dispositif de réalité augmentée axé sur l’avenir de l’audition.
Il porte le nom de code Wolverine, une référence aux sens aiguisés du mutant (et à l’un des personnages préférés du chef de projet, selon une source). L’équipe de Wolverine a commencé à travailler sur le projet en 2018, et les sources disent qu’une grande partie du travail a été concentrée sur l’itération d’un dispositif qui donnerait aux porteurs des capacités auditives améliorées. L’une des « fonctionnalités » initiales que l’équipe s’est efforcée de résoudre est la ségrégation de la parole, permettant au porteur de se concentrer sur un orateur particulier dans un contexte de groupe avec des conversations qui se chevauchent.
Même si le projet n’en est encore finalisé, des sources indiquent que Wolverine a pris de l’ampleur et a recruté quelques noms notables, dont Simon Carlile, ancien vice-président de Starkey Hearing Technologies, en tant que responsable technique.


Dans le passé, les fondateurs de Google avait un réel penchant pour les robots. À tel point qu’en 2013, le géant s’est lancé dans une frénésie de dépenses pour des entreprises de robotique, dont Boston Dynamics. Mais ces rêves se sont effondrés et, en 2017, Google a vendu Boston Dynamics au conglomérat technologique japonais SoftBank ; mais le rêve était toujours là…
Aujourd’hui, les aspirations de l’entreprise en matière de robots pourraient se raviver, mais avec une touche de nouveauté. En 2019, X a annoncé le lancement du Everyday Robot Project, une initiative visant à construire des robots qui peuvent être « enseignés » plutôt que simplement codés.
Lire l’article de ce blog :
Introducing the Everyday Robot Project
Le projet teste actuellement ses robots dans des environnements de travail en Californie du Nord et les premiers résultats seraient « encourageants », les robots effectuant des tâches telles que le recyclage (plutôt lentement, selon l’équipe).
À terme, le projet Everyday Robotics pourrait permettre à Alphabet de concurrencer la propre initiative robotique d’Amazon.
Plus d’information : Introducing the everyday robot project
Ce projet serait supervisé par Wendy Tan White, qui a rejoint X en 2019. Vice-présidente de X et « mentor moonshot », elle a pris en charge le projet de Dean Banks, qui a quitté son poste chez X pour devenir le PDG de Tyson Foods.
Une source a déclaré que le projet était susceptible de devenir une filiale autonome d’Alphabet cette année. Une porte-parole de X n’a pas fait de commentaires sur les spécificités du projet, mais a confirmé qu’il existait d’autres projets de robotique en addition à Everyday.

Expanding global access to fast, affordable internet with beams of light
Élargir l’accès mondial à un internet rapide et abordable grâce à des faisceaux lumineux
Increasing access to the internet will require affordable, reliable, and scalable infrastructure.
Global internet traffic is projected to grow 24% annually. Fiber-optic cable can support this growth in demand, but rolling out an extensive fiber network often means deployment complications. Planning and digging trenches to lay lines can be time-consuming and costly, and tough terrain can pose physical challenges that make expansion nearly impossible. Because of the difficulties laying fiber in some places, there’s a significant divide in mobile internet speeds between the countries with the fastest internet and those with the slowest.
L’élargissement de l’accès à l’internet nécessitera une infrastructure abordable, fiable et évolutive.
Le trafic Internet mondial devrait augmenter de 24 % par an. Le câble à fibre optique peut répondre à cette croissance de la demande, mais le déploiement d’un vaste réseau de fibre optique entraîne souvent des complications. La planification et le creusement de tranchées pour poser les lignes peuvent prendre du temps et être coûteux, et les terrains difficiles peuvent poser des défis physiques qui rendent l’expansion presque impossible. En raison des difficultés liées à la pose de la fibre optique dans certains endroits, il existe un écart important entre les vitesses de l’internet mobile dans les pays où l’internet est le plus rapide et ceux où il est le plus lent.
SmartyPants est un projet dont X n’est pas encore prêt à être évoquer, mais quelques indices s’échappent ici et là. Jusqu’à présent, nous savons qu’il s’agit littéralement d’un pantalon qui peut améliorer la mobilité des personnes éprouvant des difficultés à marcher, en utilisant une combinaison de robotique, d’IA, d’apprentissage automatique et de tissu.
Le pantalon « voit » son environnement en utilisant une combinaison de capteurs et d’apprentissage automatique, aidant le porteur à se déplacer en toute sécurité. Certaines offres d’emploi pour les projets révèlent également des indices sur le projet.
L’équipe semble être multidisciplinaire, réunissant des compétences en apprentissage automatique, en biomécanique, en robotique et en produits souples. Le projet est dans une phase de prototypage, en itérant rapidement et en mettant en œuvre des idées pour dé-risquer progressivement l’idée d’un point de vue technique.
SmartyPants a également fait une apparition dans une vidéo officielle que la société a publiée l’année dernière et qui plongeait dans le laboratoire de prototypage de X.
Tidal is X’s ocean conservation project, which aims to make fish farming more sustainable.
Tidal est le projet de conservation des océans de X, qui vise à rendre la pisciculture plus durable.
L’initiative utilise des caméras et des « outils de perception automatique » pour surveiller et interpréter le comportement des poissons non visibles à l’œil nu. Au fil du temps, ces données peuvent aider les pisciculteurs à gérer plus efficacement leurs enclos.
« Nous ne pouvons pas protéger ce que nous ne comprenons pas », a écrit le PDG de Tidal, Neil Davé, dans un billet de blog publié l’année dernière pour lancer le projet. « La pollution et les pratiques de pêche non durables signifient qu’il y aura bientôt plus de plastique que de poissons dans la mer, tandis que l’acidification rapide tue les coraux et les créatures marines. »
The initiative uses cameras and « automatic perception tools » to monitor and interpret the behavior of fish not visible to the naked eye. Over time, this data can help fish farmers manage their pens more effectively.
« We can’t protect what we don’t understand, » wrote Tidal CEO Neil Davé in a blog post last year to launch the project. « Pollution and unsustainable fishing practices mean that there will soon be more plastic than fish in the sea, while rapid acidification is killing corals and sea creatures. »
Plus d’informations : Introducing Tidal
Visuel des entreprises citée dans la partie ci-dessus :




En fouillant les publications de Google AI Blog, je suis tombé sur ce petit billet : Meena
Modern conversational agents (chatbots) tend to be highly specialized — they perform well as long as users don’t stray too far from their expected usage. To better handle a wide variety of conversational topics, open-domain dialog research explores a complementary approach attempting to develop a chatbot that is not specialized but can still chat about virtually anything a user wants. Besides being a fascinating research problem, such a conversational agent could lead to many interesting applications, such as further humanizing computer interactions, improving foreign language practice, and making relatable interactive movie and videogame characters. However, current open-domain chatbots have a critical flaw — they often don’t make sense. They sometimes say things that are inconsistent with what has been said so far, or lack common sense and basic knowledge about the world. Moreover, chatbots often give responses that are not specific to the current context. For example, “I don’t know,” is a sensible response to any question, but it’s not specific. Current chatbots do this much more often than people because it covers many possible user inputs. In “Towards a Human-like Open-Domain Chatbot”, we present Meena, a 2.6 billion parameter end-to-end trained neural conversational model. We show that Meena can conduct conversations that are more sensible and specific than existing state-of-the-art chatbots. Such improvements are reflected through a new human evaluation metric that we propose for open-domain chatbots, called Sensibleness and Specificity Average (SSA), which captures basic, but important attributes for human conversation. Remarkably, we demonstrate that perplexity, an automatic metric that is readily available to any neural conversational models, highly correlates with SSA.
Meena is an end-to-end, neural conversational model that learns to respond sensibly to a given conversational context. The training objective is to minimize perplexity, the uncertainty of predicting the next token (in this case, the next word in a conversation). At its heart lies the Evolved Transformer seq2seq architecture, a Transformer architecture discovered by evolutionary neural architecture search to improve perplexity. Concretely, Meena has a single Evolved Transformer encoder block and 13 Evolved Transformer decoder blocks as illustrated below. The encoder is responsible for processing the conversation context to help Meena understand what has already been said in the conversation. The decoder then uses that information to formulate an actual response. Through tuning the hyper-parameters, we discovered that a more powerful decoder was the key to higher conversational quality.
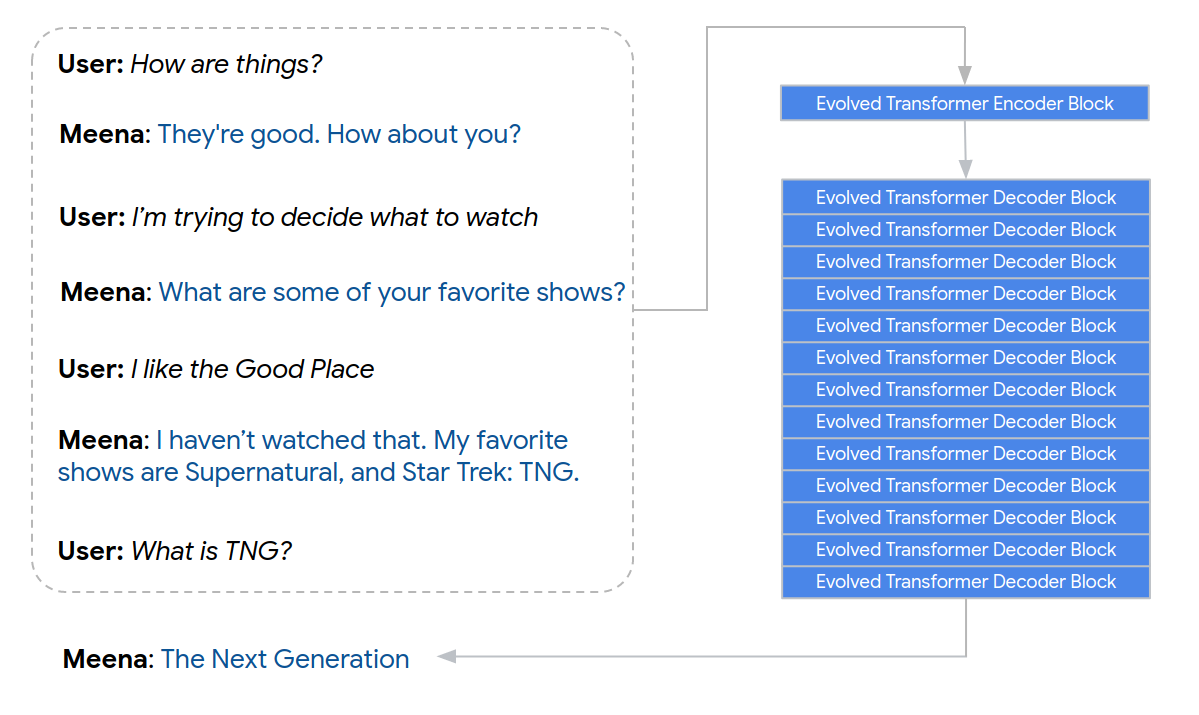 |
| Example of Meena encoding a 7-turn conversation context and generating a response, “The Next Generation”. |
Conversations used for training are organized as tree threads, where each reply in the thread is viewed as one conversation turn. We extract each conversation training example, with seven turns of context, as one path through a tree thread. We choose seven as a good balance between having long enough context to train a conversational model and fitting models within memory constraints (longer contexts take more memory). The Meena model has 2.6 billion parameters and is trained on 341 GB of text, filtered from public domain social media conversations. Compared to an existing state-of-the-art generative model, OpenAI GPT-2, Meena has 1.7x greater model capacity and was trained on 8.5x more data.
Les agents conversationnels modernes (chatbots) ont tendance à être hautement spécialisés – ils fonctionnent bien tant que les utilisateurs ne s’éloignent pas trop de l’usage prévu. Afin de mieux gérer une grande variété de sujets de conversation, la recherche sur le dialogue à domaine ouvert explore une approche complémentaire en tentant de développer un chatbot qui n’est pas spécialisé mais qui peut néanmoins discuter de pratiquement tout ce que souhaite un utilisateur. Outre le fait qu’il s’agit d’un problème de recherche fascinant, un tel agent conversationnel pourrait déboucher sur de nombreuses applications intéressantes, comme l’humanisation des interactions entre ordinateurs, l’amélioration de la pratique des langues étrangères et la création de personnages interactifs de films et de jeux vidéo. Cependant, les chatbots actuels du domaine ouvert présentent un défaut critique : ils n’ont souvent aucun sens. Ils disent parfois des choses qui ne correspondent pas à ce qui a été dit jusqu’à présent, ou manquent de bon sens et de connaissances de base sur le monde. De plus, les chatbots donnent souvent des réponses qui ne sont pas spécifiques au contexte actuel. Par exemple, « Je ne sais pas » est une réponse sensée à toute question, mais elle n’est pas spécifique. Les chatbots actuels le font beaucoup plus souvent que les humains car ils couvrent de nombreuses entrées possibles de l’utilisateur. Dans « Towards a Human-like Open-Domain Chatbot », nous présentons Meena, un modèle conversationnel neuronal entraîné de bout en bout de 2,6 milliards de paramètres. Nous montrons que Meena peut mener des conversations plus sensibles et plus spécifiques que les chatbots de pointe existants. Ces améliorations sont reflétées par une nouvelle mesure d’évaluation humaine que nous proposons pour les chatbots de domaine ouvert, appelée Sensibleness and Specificity Average (SSA), qui capture des attributs de base, mais importants pour la conversation humaine. De manière remarquable, nous démontrons que la perplexité, une métrique automatique facilement accessible à tout modèle conversationnel neuronal, est fortement corrélée à la SSA.
Meena est un modèle conversationnel neuronal de bout en bout qui apprend à répondre de manière sensible à un contexte conversationnel donné. L’objectif de la formation est de minimiser la perplexité, c’est-à-dire l’incertitude liée à la prédiction du prochain jeton (dans ce cas, le prochain mot dans une conversation). Au cœur du système se trouve l’architecture seq2seq du transformateur évolué, une architecture de transformateur découverte par recherche d’architecture neuronale évolutionnaire pour améliorer la perplexité. Concrètement, Meena possède un seul bloc d’encodeur Evolved Transformer et 13 blocs de décodeur Evolved Transformer, comme illustré ci-dessous. L’encodeur est chargé de traiter le contexte de la conversation pour aider Meena à comprendre ce qui a déjà été dit dans la conversation. Le décodeur utilise ensuite ces informations pour formuler une réponse réelle. En ajustant les hyperparamètres, nous avons découvert qu’un décodeur plus puissant était la clé d’une meilleure qualité de conversation.
Exemple de Meena encodant un contexte de conversation à 7 tours et générant une réponse, « La prochaine génération ».
Les conversations utilisées pour l’entraînement sont organisées sous forme de fils d’arbre, où chaque réponse dans le fil est considérée comme un tour de conversation. Nous extrayons chaque exemple de formation de conversation, avec sept tours de contexte, comme un chemin à travers un fil d’arbre. Nous avons choisi sept comme un bon équilibre entre un contexte suffisamment long pour entraîner un modèle conversationnel et l’adaptation des modèles aux contraintes de mémoire (les contextes plus longs prennent plus de mémoire).
Le modèle Meena possède 2,6 milliards de paramètres et a été entraîné sur 341 Go de texte, filtré à partir de conversations de médias sociaux du domaine public. Comparé à un modèle génératif de pointe existant, OpenAI GPT-2, Meena a une capacité de modèle 1,7 fois supérieure et a été entraîné sur 8,5 fois plus de données.
Je ne propose que le début de cette note ; la totalité est disponible sur : Towards a Conversational Agent that Can Chat About…Anything
Ceci est très intéressant … mais je n’ai pas trouver d’application réelle à ce jour.

Explore what’s around you in an entirely new way. Explorez ce qui vous entoure d’une manière entièrement nouvelle.
Translate text in real time, look up words, add events to your calendar, call a number, and more. Or just copy and paste to save some time.
Traduisez du texte en temps réel, recherchez des mots, ajoutez des événements à votre calendrier, appelez un numéro, etc. Ou bien copiez et collez simplement pour gagner du temps.
See an outfit that caught your eye? Or a chair that’s perfect for your living room? Get inspired by similar clothes, furniture, and home decor—without having to describe what you’re looking for in a search box.
Vous avez vu une tenue qui a attiré votre attention ? Ou une chaise qui convient parfaitement à votre salon ? Laissez-vous inspirer par des vêtements, des meubles et des objets de décoration similaires, sans avoir à décrire ce que vous recherchez dans un champ de recherche.
Wondering what to order at a restaurant? Look up dishes and see what’s popular, right on the menu, with photos and reviews from Google Maps.
Vous vous demandez ce que vous allez commander dans un restaurant ? Recherchez des plats et voyez ce qui est populaire, directement sur le menu, avec des photos et des avis provenant de Google Maps.
Learn more about popular landmarks. See ratings, hours of operation, historical facts and more.
Apprenez-en davantage sur les points de repère populaires. Consultez les classements, les heures d’ouverture, les faits historiques et bien plus encore.
Find out what plant is in your friend’s apartment, or what kind of dog you saw in the park.
Découvrez quelle plante se trouve dans l’appartement de votre ami, ou quel genre de chien vous avez vu dans le parc.
Stuck on a problem? Quickly find explainers, videos, and results from the web for math, history, chemistry, biology, physics, and more.
Vous êtes coincé sur un problème ? Trouvez rapidement des explications, des vidéos et des résultats sur le web pour les mathématiques, l’histoire, la chimie, la biologie, la physique, etc.

La sélection peut être ajustée manuellement, et vous ne serez alors plus qu’à un clic de pouvoir copier le texte dans le presse-papiers de votre machine, pour ensuite le coller dans un éditeur de texte, un e-mail, sur les réseaux sociaux, etc. Pour l’heure, seule la reconnaissance optique de caractères de Google Lens est disponible sur le Web.
Google Lens est gratuit !
Allez sur le site Google Lens et cliquez sur le bouton Download.
C’est tout simplement si facile !
Google Lens pourra bientôt déchiffrer l’écriture de votre médecin
Google a fait une démonstration dans laquelle son module de recherche visuel a été capable de déchiffrer une ordonnance manuscrite d’un médecin.
Publié sur 01Net par Geoffroy Ondet le 19 décembre 2022
Grâce à l’intelligence artificielle, le module de recherche visuelle de Google voit ses capacités décuplées. Google Lens est capable de rechercher tout ce que vos yeux peuvent voir, et peut même dans certains cas vous aider à identifier certains problèmes de santé.
Sans qu’elle puisse être clairement utilisée pour un diagnostic précis, Google Lens peut maintenant vous aider à identifier certaines pathologies. En particulier les problèmes dermatologiques. Vous pouvez désormais soumettre une photo de votre peau à Google Lens pour lui faire rechercher des images correspondant visuellement au problème qui vous touche. Vous avez remarqué des rougeurs suspectes sur votre peau ? Prenez-la simplement en photo et soumettez l’image à Google Lens. Le module recherchera alors les correspondances visuelles qui vous permettront, peut-être, d’identifier un eczéma ou un psoriasis. Attention toutefois, si le module peut sans doute vous rassurer quant à la pathologie qui vous touche, il ne remplacera en rien l’avis d’un professionnel de santé.

Un projet de recherche open source qui explore le rôle de l’apprentissage automatique comme outil dans le processus créatif.
Les 4 modules actuellement proposés :
MusicVAE
Creating palettes for blending and exploring musical loops and scores.
Learn more.
Magenta was started by researchers and engineers from the Google Brain team, but many others have contributed significantly to the project. We develop new deep learning and reinforcement learning algorithms for generating songs, images, drawings, and other materials. But it’s also an exploration in building smart tools and interfaces that allow artists and musicians to extend their processes using these models. We use TensorFlow and release our models and tools in open source on our GitHub.
Magenta a été lancé par des chercheurs et des ingénieurs de l’équipe Google Brain, mais de nombreuses autres personnes ont contribué de manière significative au projet. Nous développons de nouveaux algorithmes d’apprentissage profond et d’apprentissage par renforcement pour générer des chansons, des images, des dessins et d’autres matériaux. Mais c’est aussi une exploration dans la construction d’outils et d’interfaces intelligents qui permettent aux artistes et aux musiciens d’étendre leurs processus en utilisant ces modèles.
Le Blog Google Research du projet : Magenta
Le site web du projet (démo possible) : Magenta
Le lient GitHub des sources : Source Magenta

