The ultimate goal of AI research is to build technologies that benefit humans — from assisting us with quotidian tasks to addressing grand existential challenges facing society1. Machine learning systems have already solved major problems in biomedicine2, and helped address humanitarian and environmental challenges. However, an underexplored frontier is the deployment of AI to help humans design fair and prosperous societies5. In economics and game theory, the field known as mechanism design studies how to optimally control the flow of wealth, information or power among incentivized actors to meet a desired objective, for example by regulating markets, setting taxes or aggregating electoral votes. Here we asked whether a deep reinforcement learning (RL) agent could be used to design an economic mechanism that is measurably preferred by groups of incentivized humans.
The challenge of building AI systems whose behaviour is preferred by humans is called the problem of ‘value alignment’. One key hurdle for value alignment is that human society admits a plurality of views, making it unclear to whose preferences AI should align. For example, political scientists and economists are often at loggerheads over which mechanisms will make our societies function most fairly or efficiently. In AI research, there is a growing realization that to build human-compatible systems, we need new research methods in which humans and agents interact, and an increased effort to learn values directly from humans to build value-aligned AI. Capitalizing on this idea, here we combined modern deep RL with an age-old technology for arbitrating among conflicting views—majoritarian democracy among human voters—to develop a human-centred research pipeline for value-aligned AI research. Instead of imbuing our agents with purportedly human values a priori, and thus potentially biasing systems towards the preferences of AI researchers, we train them to maximize a democratic objective: to design policies that humans prefer and thus will vote to implement in a majoritarian election. We call our approach, which extends recent related participatory approaches, ‘Democratic AI’.
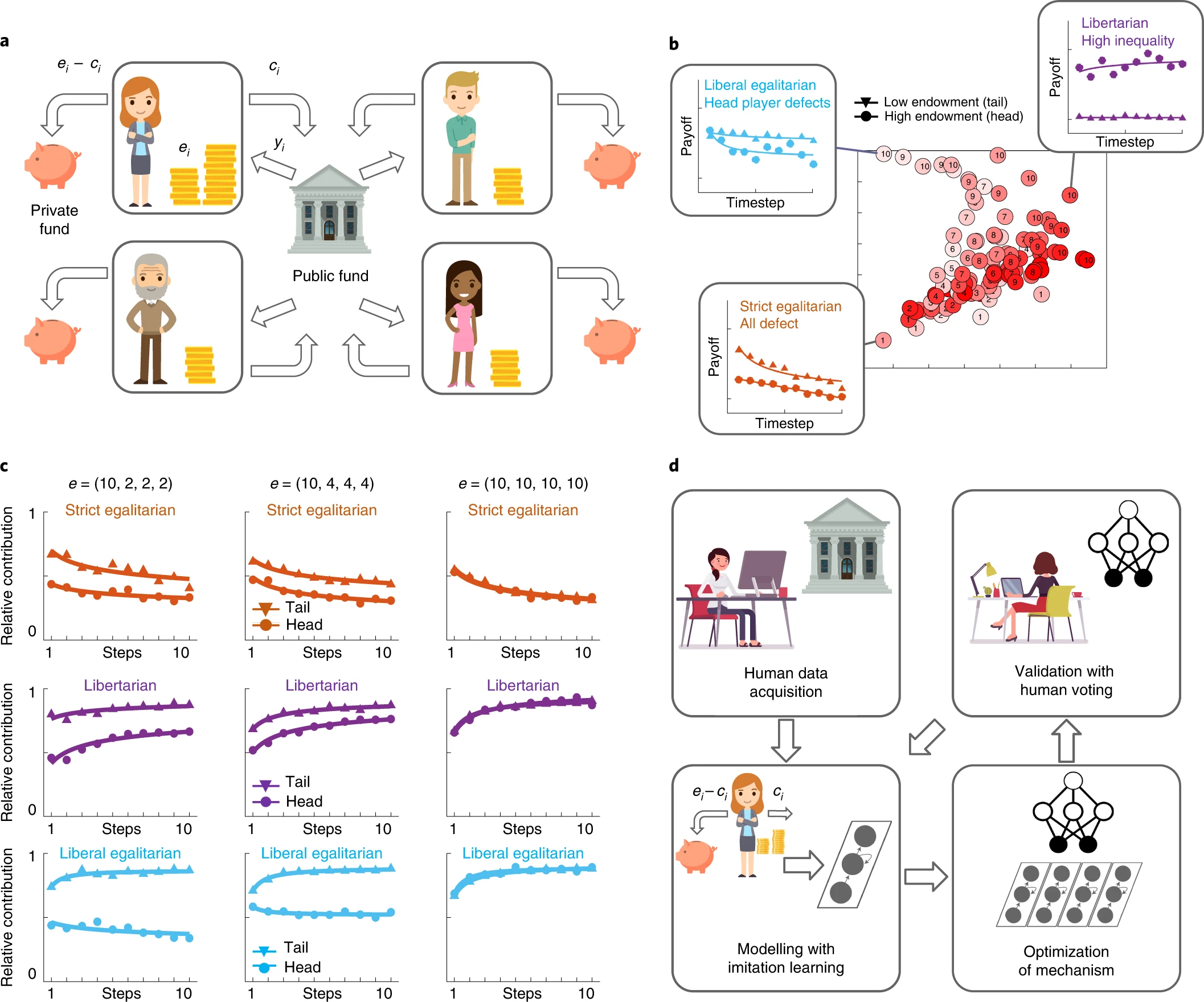
As a first rigorous test, we deploy Democratic AI to address a question that has defined the major axes of political agreement and division in modern times: when people act collectively to generate wealth, how should the proceeds be distributed?. We asked a large group of humans to play an incentive-compatible online investment game that involved repeated decisions about whether to keep a monetary endowment or to share it with other players for potential collective benefit. We trained a deep RL agent to design a redistribution mechanism which shared funds back to players under both wealth equality and inequality. The mechanism it produced was ultimately preferred by the players in a majoritarian election.